12
ArchiveBox
Self Webbarkivet med självhosting med öppen källkod.Tar webbläsarhistorik / bokmärken / Pocket / Pinboard / etc., Sparar HTML, JS, PDF-filer, media och mer.
- Gratis
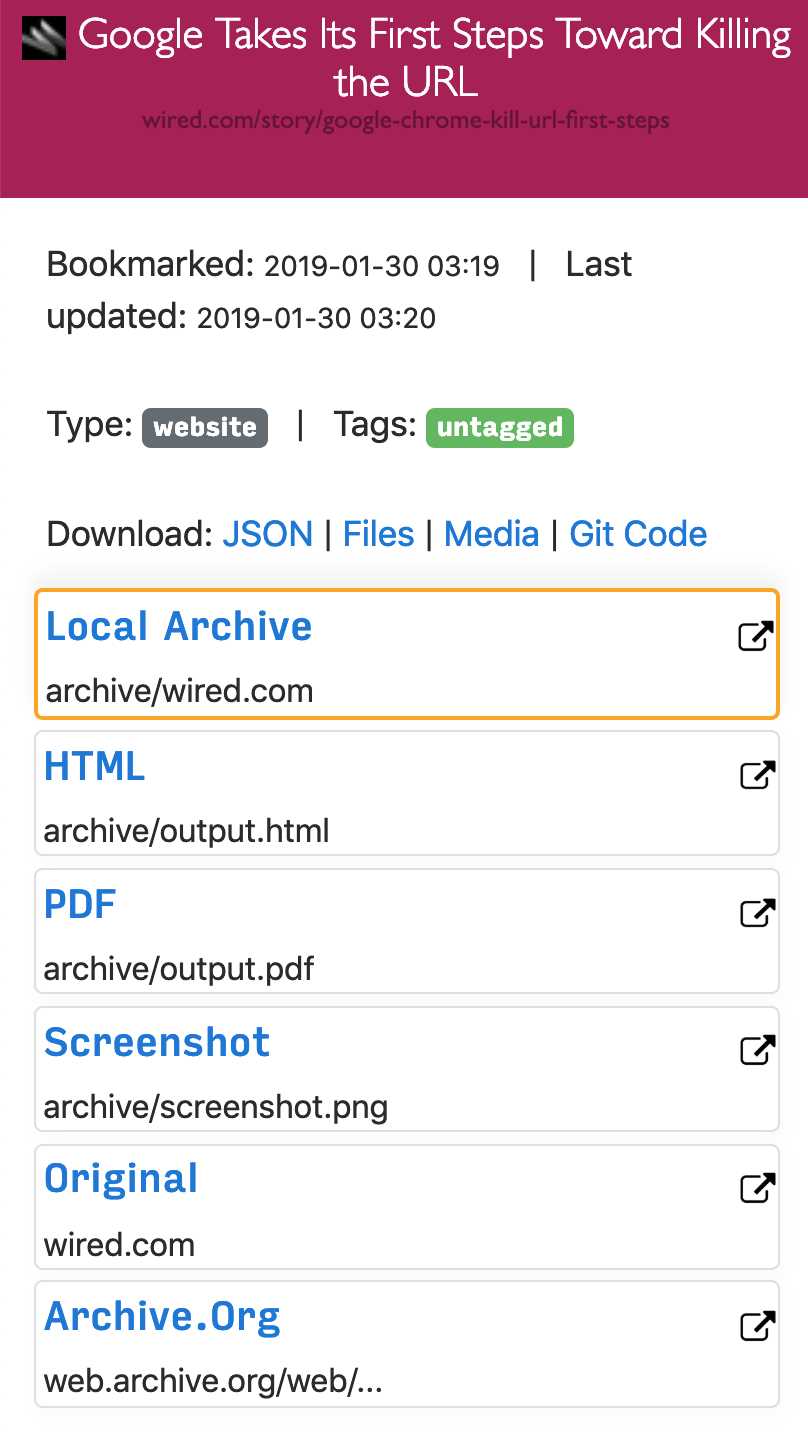
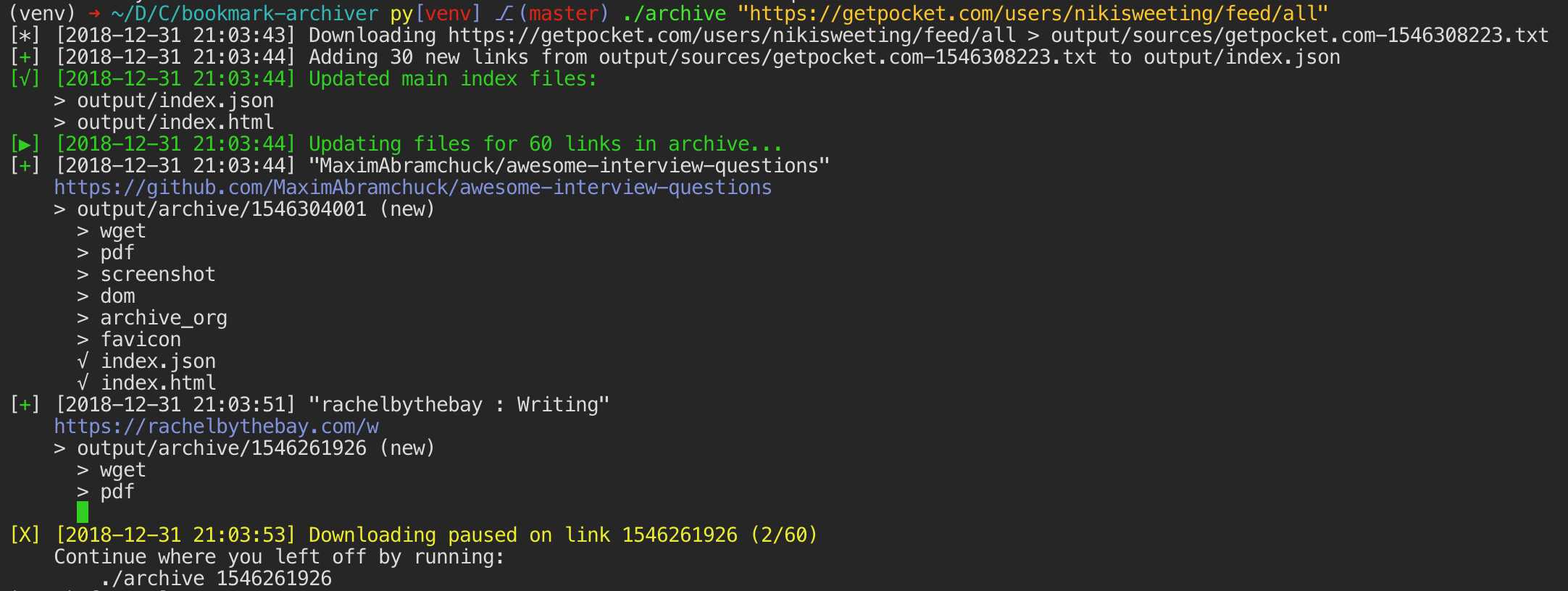
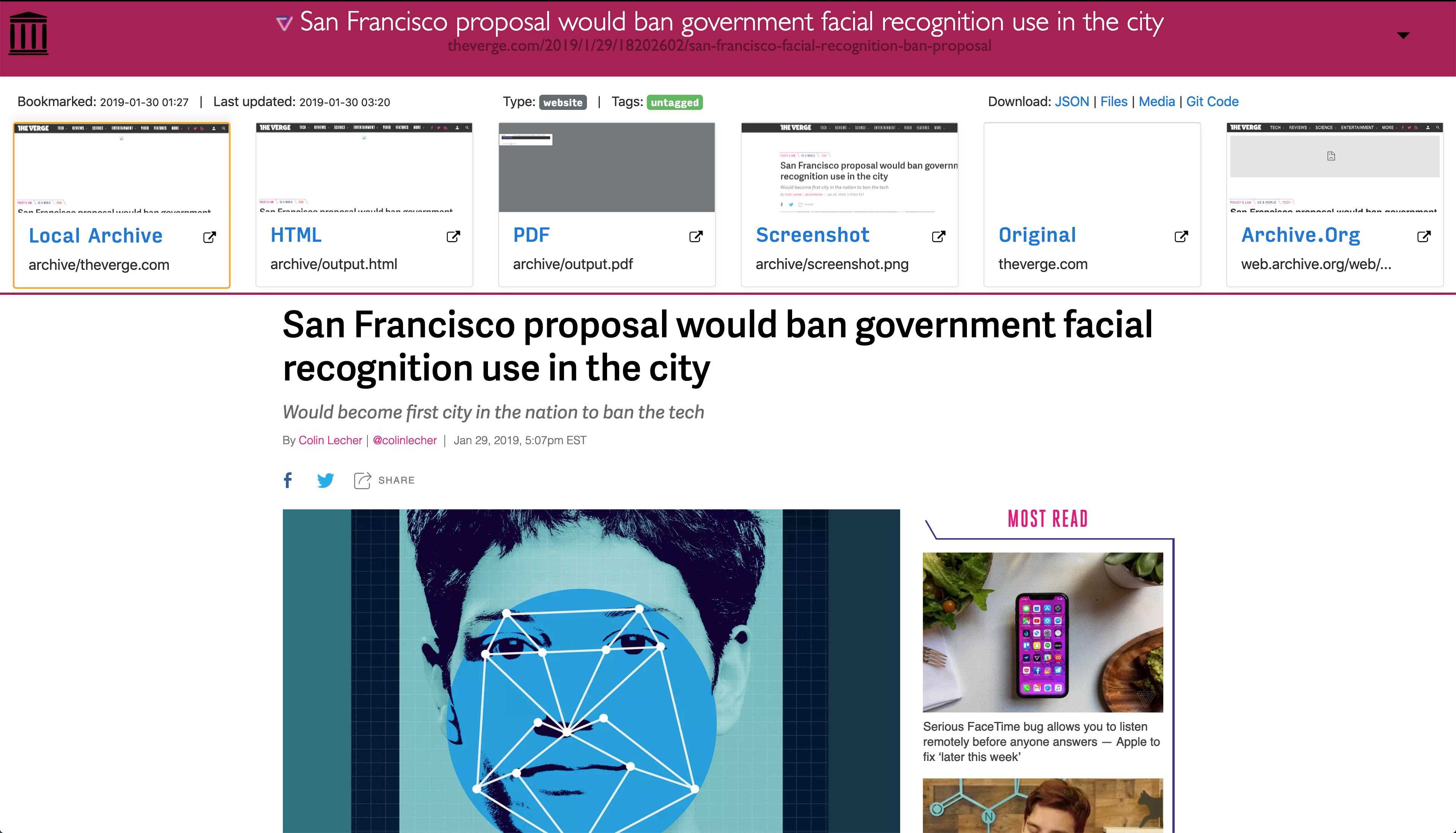
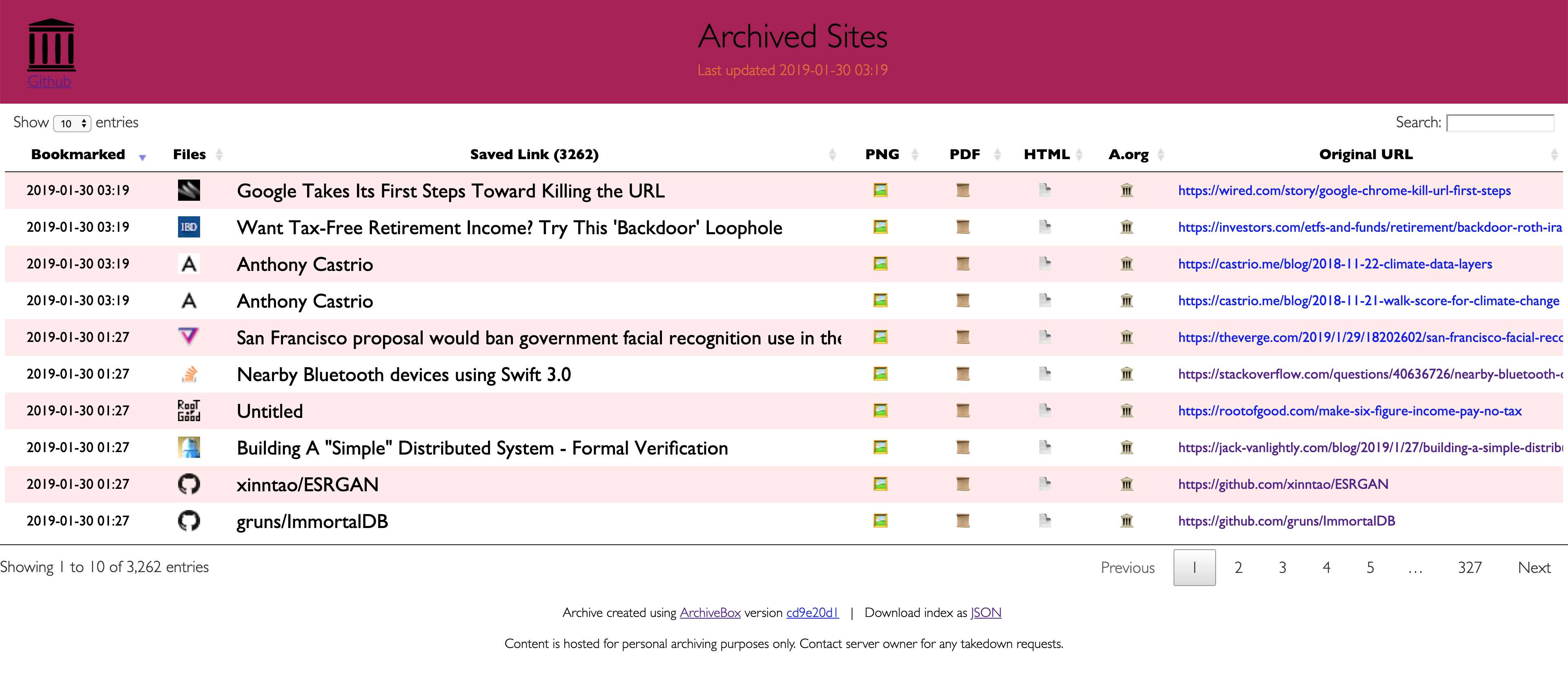
Eftersom moderna webbplatser är komplicerade och ofta förlitar sig på dynamiskt innehåll arkiverar ArchiveBox webbplatserna i flera olika format utöver vad offentliga arkiveringstjänster som Archive.org och Archive.is kan spara.ArchiveBox importerar en lista med webbadresser från stdin, fjärr url eller fil, lägger sedan sidorna till en lokal arkivmapp med wget för att skapa en sökbar html-klon, youtube-dl för att extrahera media och en fullständig instans av Chrome headless för PDF,Skärmdump och DOM-dumpningar och mer ... Med flera metoder och den marknadsdominerande webbläsaren för att köra JS säkerställer vi att vi kan spara till och med de mest komplexa, känsliga webbplatserna i minst några högkvalitativa, långsiktiga dataformat.### Kan importera länkar från: - Pocket, Pinboard, Instapaper - RSS, XML, JSON eller vanlig textlistor - Browserhistorik eller bokmärken (Chrome, Firefox, Safari, IE, Opera och mer) - Shaarli, Delicious, RedditSparade inlägg, Wallabag, Unmark.it och annan text med länkar i den!### Kan spara dessa saker för varje webbplats: - "favicon.ico" -favikon för webbplatsen - "example.com / page-name.html" wget-klon på webbplatsen, med .html bifogad om inte finns - "output.pdf` Tryckt PDF av webbplatsen med hjälp av headless chrome - `screenshot.png` 1440x900 skärmdump av webbplatsen med headless chrome -` output.html` DOM Dump av HTML efter rendering med headless chrome - `archive.org.txt` En länk tillsparad webbplats på archive.org - `warc /` för html + gzipped warc-filen.gz - `media /` alla mp4-, mp3-, undertexter och metadata som hittas med hjälp av youtube-dl - `git /` klon i vilket arkiv som helst för github, bitbucket eller gitlab-länkar - `index.html` &` index.json`HTML- och JSON-indexfiler som innehåller metadata och detaljer Arkiveringen är additiv, så att du kan schemalägga `. / Arkiv` att köra regelbundet och dra nya länkar till indexet.Allt det sparade innehållet är statiskt och indexeras med JSON-filer, så det lever för alltid och är lätt parsbart, det kräver ingen backend som alltid körs.
kategorier
Alternativ till ArchiveBox för alla plattformar med någon licens
785
Spara webbsidor för att läsa senare och eliminera röran med bokmärken med webbplatser som bara är en engångsintresse.
358
284
191
Wayback Machine
Bläddra igenom över 150 miljarder webbsidor arkiverade från 1996 till några månader sedan.
184
wallabag
wallabag är en open source-egen värdbar applikation för att spara webbsidor. ## Bekväm läsning
124
67
Evernote Web Clipper
Spara allt du ser online - inklusive text, länkar och bilder - på ditt Evernote-konto med ett enda klick.
67
Archive.is
Archive.is låter dig "ta ett foto" av en webbsida som alltid kommer att finnas tillgänglig även om den ursprungliga sidan ändras eller raderas.
- Gratis
- Web
66
Internet Archive
Internet Archive är ett ideellt digitalt bibliotek som erbjuder gratis universell tillgång till böcker, filmer och musik samt 150 miljarder arkiverade webbsidor.
- Gratis
- Web
19
17
SiteSucker
macOS-applikation som automatiskt laddar ner webbplatser från Internet.Det gör detta genom att asynkront kopiera webbplatsens webbsidor, bilder, PDF-filer, stilark och andra filer till din lokala hårddisk, genom att duplicera webbplatsens katalogstruktur.
14
PageArchiver
PageArchiver (tidigare kallad "Scrapbook for SingleFile") är en Chrome-förlängning som hjälper dig att arkivera webbsidor för offlineläsning. Huvudfunktioner är:
7
Reminiscence
Själv värd bokmärke och arkivhanterare.Bokmärke länkar och redigera dess metadata (som titel, taggar, sammanfattning) via webbgränssnitt.
- Gratis
- Self-Hosted
3